A selection of our clients









The firm's data ecosystem, in one intelligent engine.
Integrate all internal and external data sources into a living, learning data engine built to optimize dealmaking and drive sustained competitive advantage for your firm.
.svg)


Helping tech leadership get data in the fast lane
Our purpose-built data engine pulls together your entire market and proprietary data ecosystem, fueling your AI roadmap.

Agentic AI for PE, from origination to value creation
Empower origination teams with codified scoring, net-new recommendations, watchlists and tracked deals.
Connecting the unconnected in dealmaking
Unifying the data, intelligence, and signals that exist for private equity firms, and transforming it into deals.
Finally, a platform your firm can truly customize
Deal Engine is offered as a white-labelled solution, resulting in faster onboarding, adoption, brand alignment and organizational buy-in.
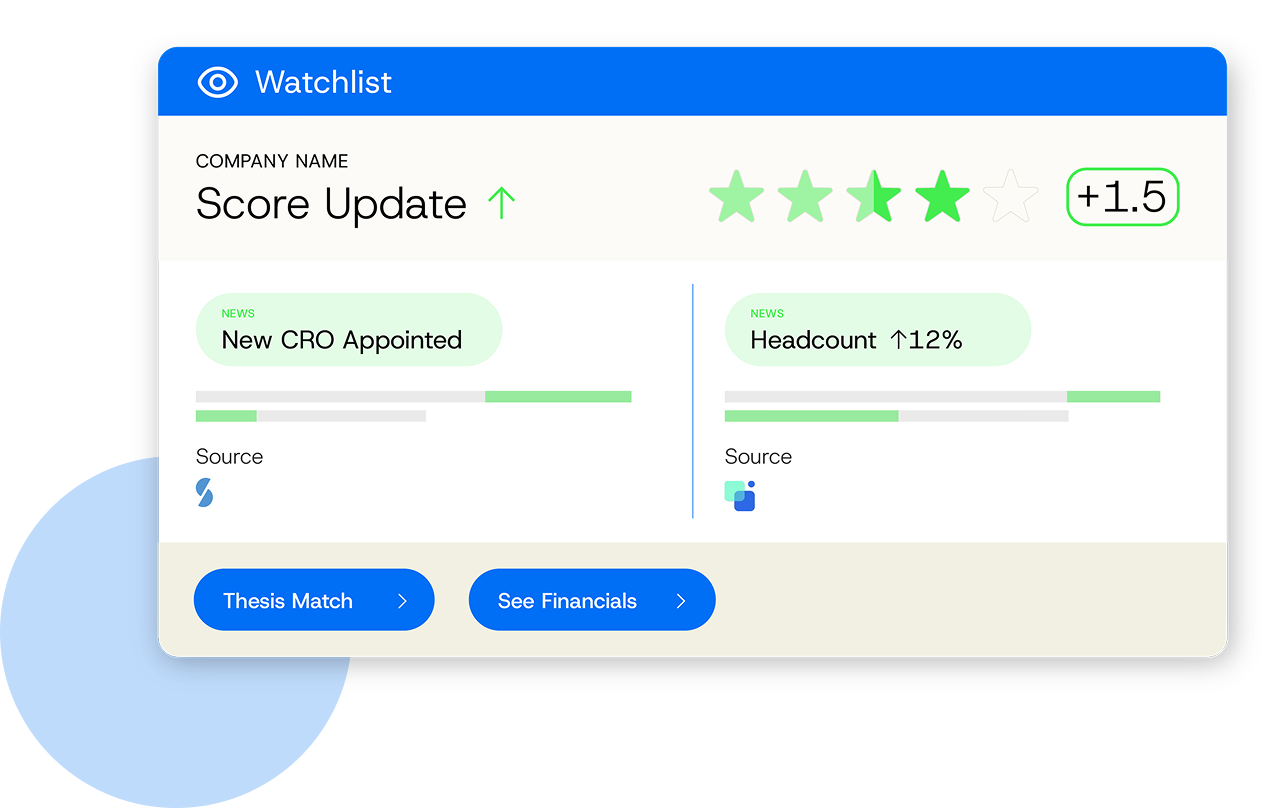
Find more net new deals for your firm
Codify your strategy, track the market and increase relevance. Deal Engine delivers always-on agentic AI intelligence that continuously monitors your entire investable universe — specified by your thesis — and surfaces high-fit targets.
Unify data, unlock insights
White-label the technology and make your Deal Engine entirely yours. Deal Engine brings together proprietary, third-party, and public data into a single connected layer, transforming information into actionable intelligence.

Power up instead of piling on
Optimize your data spend and unlock the value in your CRM and internal documents. Deal Engine enriches your CRM with structured, intelligent data without adding clutter, complimenting your existing tech stack instead of complicating it.
Build the gen AI-enabled firm of tomorrow
Fuel your AI roadmap with an integrated agentic AI intelligence layer. Accumulate and train your firm’s own proprietary dealmaking engine, built to evolve with your strategy and scale firm-wide tech-readiness.
.png)
What mid market private equity leaders are getting right about AI
WATCH: From AI experimentation to institutional advantage in mid-market private equity Artificial intelligence is no longer a theoretical discussion in private equity. Foundational models are advancing quickly, AI capabilities are being embedded into core systems, and firms are under increasing pressure from LPs to demonstrate that they are building modern, technology-enabled origination capabilities. At the same time, many mid-market firms are discovering that layering AI onto existing systems does not automatically translate into better deal flow, stronger prioritization, or faster decision-making. The difference between firms seeing measurable impact and those still experimenting often has less to do with model sophistication and more to do with something less visible: whether their underlying data environment has the context to accurately reflect their investment strategy. In two recent conversations (videos below), Alex Bajdechi and Phil Westcott shared what they are observing across the market and why the next phase of competitive advantage in private equity will be shaped more by data architecture than by model access alone. The operational gap between AI ambition and reality {% video_player "embed_player" overrideable=False, type='hsvideo2', hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width='1280', height='720', player_id='374367046844', style='' %} Deal Engine Global VP of Sales, Alex Bajdechi, talking about PE firms and what they need to win in such a tech-enabled world getting to grips with AI, tools, data, context integration and more. Most mid-market private equity firms already operate with a substantial technology stack. They license third-party datasets, maintain a CRM, track opportunities, and build target company lists. On paper, the components required for AI-enabled origination appear to be in place. In practice, the operating reality inside deal teams is often more fragmented. Alex Bajdechi, Global VP of Sales at Deal Engine, has spent years working closely with private equity firms navigating CRM strategy and origination workflows. A consistent pattern emerges: investment thinking and investment data are rarely tightly aligned. Sector theses are often articulated in slide decks. Investment criteria live in narrative documents. Historical deal knowledge sits in free-text CRM notes. Market intelligence resides in external platforms that are not fully integrated. The firm’s edge exists, but it is distributed and inconsistently structured. When AI is introduced into this environment, expectations are understandably high. However, if the underlying data is incomplete, inconsistent, or disconnected, AI outputs will inevitably reflect those constraints. Teams begin to question reliability. Results require manual validation. Momentum slows. This dynamic explains why many firms remain stuck in reactive patterns. They respond to inbound opportunities rather than systematically hunting against defined criteria. They move across disconnected applications that do not meaningfully communicate. They build lists that loosely reference strategy but are not rigorously anchored to it. They experiment with AI tools without seeing durable change in workflow. These outcomes are not a failure of AI technology. They are a reflection of the fact that AI systems can only reason over the structure and context they are given. Firms beginning to see consistent impact are addressing the issue at a foundational level. Rather than prioritizing additional tools, they are translating their investment strategy into structured data. They are aligning CRM history, company tracking, market intelligence, and proprietary insights into a unified operating layer that mirrors how the firm evaluates opportunity. For many mid-market funds, this does not require rebuilding from scratch. A significant proportion of the relevant data already exists internally. The shift lies in organizing and governing that data so it becomes coherent, auditable, and directly aligned to strategy. When that alignment is in place, AI becomes less experimental and more operational. Turning implicit judgment into structured institutional intelligence {% video_player "embed_player" overrideable=False, type='hsvideo2', hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width='1920', height='1080', player_id='374367046846', style='' %} Deal Engine Founder and CEO Phil Westcott, talking about how, a strategic level, the challenge extends beyond integration. Every private equity firm believes it has differentiated insight. Partners develop pattern recognition through years of transactions. Teams form strong views on which business models scale, which management dynamics matter, and which signals are predictive within a given sector. The challenge is that this knowledge is often implicit. It lives in individuals’ experience, fragmented notes, or loosely structured CRM entries. It influences decisions, but it is not consistently encoded. Phil Westcott’s perspective is that if firms want AI to meaningfully enhance investment performance, this implicit knowledge must be structured and institutionalized. That process involves converting narrative theses into defined, measurable criteria. It requires mapping historical deal outcomes to structured attributes so patterns can be analyzed systematically. It means integrating CRM history, documents, and external data into a governed environment that reflects how the firm actually evaluates investments. When this work is done, AI is no longer reasoning over generic market information. It is operating within firm-specific context. Outputs become more aligned with how the partnership thinks. Insights can be traced back to defined inputs. Over time, institutional memory compounds rather than dissipates. This is the logic behind building a dedicated data engine. Not as another point solution competing for attention, but as connective infrastructure that unifies proprietary and external data into a coherent foundation. In that environment, AI becomes materially more useful because it is grounded in structured context rather than isolated datasets. From reactive deal flow to systematic signal generation One of the most practical consequences of strengthening the data foundation is a shift in how origination is executed. Relationship-driven sourcing will always remain central to private equity. However, competition for differentiated opportunities has intensified, and LPs increasingly expect firms to demonstrate discipline in how they source and prioritize investments. When investment criteria are codified and data is unified, firms can move beyond reactive workflows toward systematic signal generation. Rather than waiting for opportunities to surface, they can continuously monitor companies that match structured criteria. They can identify changes in performance, ownership, hiring patterns, or strategic direction that align with their thesis. They can prioritize outreach based on contextual triggers instead of static lists. This approach does not replace human judgment. It sharpens it. Analysts spend less time reconciling data across systems. Associates evaluate opportunities against clearly defined attributes. Partners gain visibility into how pipeline development aligns with stated strategy. AI outputs become more reliable because they are grounded in transparent inputs. Over time, origination becomes more repeatable. Institutional knowledge becomes embedded in infrastructure rather than residing solely in individuals. The firm’s AI narrative with LPs is supported by demonstrable architecture rather than isolated experiments. Building long-term AI advantage on durable foundations It is tempting to assume that competitive advantage in AI will be determined by access to the most advanced models. In reality, foundational model capabilities are improving across the industry, and access is becoming increasingly standardized. The more durable source of differentiation lies in proprietary context and disciplined data architecture. Mid-market firms that layer AI onto fragmented systems may achieve incremental improvements, but they are unlikely to unlock sustained advantage. Firms that invest in structuring and governing their data environment are building infrastructure that compounds over time. The practical question is not simply whether a firm is using AI. It is whether its data foundation accurately represents how it invests, how it sources, and how it creates value. For firms willing to address that foundation directly, AI becomes more than an overlay. It becomes an embedded extension of the firm’s strategy, integrated into everyday workflows and capable of scaling institutional intelligence. That is where enduring competitive advantage begins. Find out more about how Deal Engine helps dealmakers.
Why context engineering matters in private equity
By Martin Pomeroy, Tech Co-Founder, Deal Engine Across private equity, firms are racing to deploy large language models against their data ecosystems. CRMs, data rooms, portfolio data, third-party datasets; everything is being fed into LLMs with the hope that insight will emerge on the other side. In many cases, it doesn’t. Or worse, the output looks plausible but doesn’t meaningfully improve decision-making. The result is frustration, skepticism, and an unintended outcome: doubt about whether AI is actually fit for purpose at the firm level. The problem isn’t the models themselves, it’s the lack of context. The LLM isn’t the starting point One of the most common mistakes we see is treating the LLM as the first step in the process rather than the last. Firms ask, “What can this model tell us?” before asking the more important question: What data should it be looking at in the first place? Without disciplined pre-processing, even the best models will struggle. They’ll attempt to reconcile stale information with current signals, weigh irrelevant data alongside high-confidence inputs, and surface results that feel noisy or contradictory. That’s not an intelligence failure, it’s a systems failure. The right approach is to be deliberate about what data is passed to the model, how it’s framed, and what should be excluded entirely. This is where context engineering becomes critical, and where partners like Deal Engine play a role in helping firms operationalize it correctly. Start with the investment thesis Context engineering begins with clarity around the investment thesis. An LLM should not be searching “the universe of companies.” It should be searching your universe - defined by sector focus, size, geography, ownership structure, growth profile, and other thesis-driven constraints. That thesis provides the lens through which everything else is evaluated. Once that lens is defined, firms can establish a manual data priority system: agreed-upon rules that determine which data sources carry the most weight, which signals are disqualifying, and how classifiers and scoring models should behave. An agent without memory and context is just a text generator - this structure allows AI to operate with intent rather than ambiguity. Encoding institutional memory Another overlooked aspect of context is institutional knowledge. If a company has already been reviewed and marked non-investable in the CRM, that matters. If it was evaluated recently, resurfacing it again adds little value. Context engineering encodes these realities directly into the workflow: don’t show me what we’ve already seen, don’t revisit decisions without new signal, respect prior conclusions unless conditions change. Without this layer, LLMs will happily rediscover the same companies over and over again, technically “new,” but operationally useless. Rubbish in, rubbish out…at the token level All of this comes back to a simple principle: rubbish in, rubbish out. LLMs reason over tokens. If you overload them with loosely relevant data, conflicting timeframes, or redundant information, you increase the likelihood of confusion. Controlling tokens isn’t just about efficiency or cost, it’s about analytical clarity. Context engineering forces discipline. It ensures that only the most relevant, highest-confidence information is passed to the model, in a structure it can reason over effectively. The goal is not more data, but better data. Practical use cases: from noise to signal One practical example is generating LLM-friendly company profiles. Instead of asking a model to synthesize raw data from dozens of sources, firms can provide a normalized, thesis-aligned profile that captures what actually matters for an initial investment decision. This is especially important when searching for net-new opportunities. Deal sourcing is inherently a haystack problem - but without context, an LLM will surface a lot of useless needles. Context engineering dramatically narrows the search space so that “net new” actually means new and relevant. Predictability that enables trust and accelerates user adoption When context is properly engineered, AI becomes predictable. The same inputs produce consistent outputs. The process can be repeated, audited, and trusted. Ultimately, that’s what deal teams want: all the relevant information at a glance, presented clearly enough to make a confident yes-or-no decision. Not a black box, not a novelty, but a reliable system. The future of AI in private equity won’t be defined by who uses the biggest model. It will be defined by who asks and answers the right question first: what data are we passing to the model?To learn more about how Deal Engine has consulted firms on this very conundrum for over a decade, get in touch. Get your demo now to see how this works in practice.
The infrastructure behind AI-driven deal flow
What happens when a firm builds its own dealmaking data engine? Private equity is entering a new phase of technology maturity. Over the past decade, firms have invested heavily in data subscriptions, CRM platforms and workflow tools. More recently, attention has shifted toward AI, with many firms exploring copilots, automated screening and intelligent search. Yet as AI adoption accelerates, a structural reality is becoming clear. Access to tools is no longer a differentiator. Most firms now operate with similar third-party datasets, similar CRM infrastructure and access to the same large language models. In this environment, advantage does not come from software alone. It comes from how effectively a firm integrates its proprietary context across systems. The competitive shift is moving from tool adoption to infrastructure design. The move from tool stacking to infrastructure For many firms, technology has evolved incrementally. New tools have been layered onto existing processes to improve efficiency at specific stages of the deal lifecycle. However, AI exposes the limitations of this approach. When investment thesis logic sits in static documents, historical deal insight sits in a CRM, market intelligence sits in external platforms and scoring logic lives in spreadsheets, AI cannot unify these fragments into coherent intelligence. Layering automation onto fragmented systems increases speed, but not necessarily clarity. Firms seeing measurable progress are taking a different route. They are: Translating their investment thesis into structured, operational logic Integrating structured and unstructured data into a governed environment Aligning scoring models directly to investment criteria Training AI on proprietary deal history and institutional memory This is the foundation of a firm-owned data engine. What changes when origination infrastructure matures? When origination infrastructure is unified and thesis-aligned, the impact becomes measurable. Across typical customer deployments, we see: 64 new deals on the radar in 2 months This reflects continuous, thesis-aligned monitoring across the market. Opportunities are surfaced as relevant signals emerge, rather than waiting to be manually identified. Origination becomes systematic rather than reactive. 161 actionable insights per firm, per month Actionable insights are ranked against configured scoring rules that reflect how the firm actually invests. This reduces time spent filtering and increases time spent assessing strategic fit. 45M+ datapoints structured in a typical deployment Structured datasets, unstructured notes, news signals and third-party data are normalised and mapped to the firm’s investment framework. This creates an institutional knowledge base that compounds over time. It is this layer that enables meaningful AI application. 99.5% reduction in analyst time spent on manual research Manual monitoring and reconciliation processes are replaced by automated signal detection and unified reporting. Analysts move from data collection to interpretation, where judgement and experience add value. Why AI alone does not create advantage There is a growing assumption that rapid AI adoption will drive competitive differentiation. In reality, model access is becoming commoditised. Most firms can access the same core technologies. The differentiator is not the model. It is the quality, governance and coherence of the data foundation beneath it. AI layered onto fragmented systems accelerates inconsistency. AI applied to unified, thesis-aligned, proprietary data enhances insight. Infrastructure determines outcome. A framework for evaluating maturity For firms assessing their readiness, the following questions are useful starting points: Is the investment thesis operationalized into data, or documented narratively? Can scoring logic be centrally configured and applied consistently across the market? Are structured and unstructured data sources unified within a governed environment? Is AI trained on the firm’s proprietary deal history, or limited to public information? The answers distinguish experimentation from durable competitive advantage. Download the origination infrastructure benchmark snapshot The benchmark metrics referenced above have been compiled into a downloadable snapshot for firms reviewing their origination maturity and AI readiness. Download the PDF Private equity advantage in the coming years will not be determined by who adopts AI first. It will be shaped by who builds the most coherent, thesis-aligned and governed data foundation for AI to operate on. That is the shift from tools, to infrastructure. Find out more about how Deal Engine helps dealmakers.
From implementation to repeatable deal flow
From implementation to repeatable deal flow Implementing a data engine is only the first step, value is realized when teams know how to use it. In this interview, James Ede, who leads the client facing teams at Deal Engine, explains how private equity and corporate finance teams are building practical workflows around investment theses, internal data, and deal flow. He also shares what separates early experimentation from durable, repeatable success. Q: Post-implementation, what are the biggest workflow priorities you see client teams focusing on once Deal Engine is live? James Ede:The primary focus for most teams, especially early on, is establishing workflows around new investment thesis development and opportunity identification. While this does vary by client, a common first step is using Deal Engine to codify and operationalize the types of opportunities they want to find - rather than relying on ad-hoc searches or manual screening. Another major priority is connecting internal data sources, particularly SharePoint or similar document repositories. Giving your Deal Engine contextual access to internal materials - past investment memos, IC notes, research, and deal commentary, significantly improves the relevance and quality of results. Once that connection is in place, teams can move much faster and with greater confidence. Q: How does Deal Engine guide or coach teams on the workflows they should be establishing now that a data engine is in place? James Ede:Our approach is very hands-on and iterative. We spend time in 1:1 working sessions with team members to review how AI agents are configured and how workflows are being used in practice. Typically, we’ll start by setting up an initial agent on the client’s behalf. That agent runs against their data, and we review the outputs together - what’s working, what’s useful, and where refinements are needed. This validation step is critical because it builds trust in the results and helps teams understand why the engine is surfacing what it is. We then help clients with creation of further agents or the ability to create their own. That’s often where things really click. Teams quickly see the value of recommendation-driven workflows, where Deal Engine proactively surfaces relevant companies or insights, removing the need to manually filter, search, or second-guess whether something was missed. Q: Can you share an example (anonymized) of a client workflow you’ve found particularly effective or impressive? James Ede:Conceptually, one of the strongest workflows we see is when Deal Engine is embedded directly into the deal team’s existing operating rhythm. For example, an analyst might run a thesis-based agent that identifies a short list of new companies aligned with current investment priorities. Those results are automatically reviewed by a senior team member, enriched with internal context from prior deals or research, and then pushed into the firm’s CRM or pipeline for further evaluation. The most effective versions of this tend to be firms with strong downstream systems already in place - like a well-structured CRM - because Deal Engine becomes a natural upstream accelerator. In those cases, the engine isn’t replacing human judgment; it’s ensuring that the right opportunities are consistently surfaced, contextualized, and routed to the right people at the right time. Interested in seeing how Deal Engine clients are building repeatable, thesis-driven deal workflows? Contact us to learn how teams are operationalizing their data engines across origination, research, and execution. Get your demo now to see how this works in practice.